In this study, we explored the use of 3 different families of Large Language Models (LLMs), GPT, Claude, and Llama, to offer an accurate, expedient, and lower-cost alternative to existing methods of post-market outcome assessment for spaceOAR. We started by querying the Food and Drug Administration (FDA) Manufacturer and User Facility Device Experience (MAUDE) database for AE reports related to spaceOAR usage from August 2023 - November 2023, yielding approximately 97 reports after excluding duplicates and reports referencing multiple patients. We then classified reports based on the primary and secondary problems identified, presence of symptoms, whether symptoms initiated prior to radiation, whether there was a radiation plan delay or change, and a Common Terminology Criteria for Adverse Events (CTCAE) score. Three medical student reviewers analyzed these reports separately, and conflicts were resolved by a board certified Urologist. The resulting classifications were then used as the ground truth document for model evaluation (reference document).
We then evaluated the following LLMs: GPT-3.5-Turbo, GPT-4-Turbo, and GPT-4o (using the OpenAI API [Application Programming Interface]); Claude 3.5 Sonnet (using the Anthropic API); and the open-source models Llama3.1-70b, Llama3.1-405b, Llama3.2-3b, and Llama3.3-70b (using the Llama API). Two types of extraction prompts were created. In the first method (joint-prompt), all 6 classification tasks (identification of primary problem, secondary problem(s), presence of symptoms, delay or change in the radiation plan, symptom initiation before radiation, and CTCAE score) for the same report were requested in one large prompt. In the second method (split-prompt), each classification task was requested in a separate prompt. We iterated on each prompt format several times ("prompt engineering") in GPT-4.0 to improve the quality of output responses and gain more consistent results. Lastly, we further refined our analysis by varying the temperature (temp) parameter, which controls the randomness of responses output by the LLM, to assess its impact on data extraction. Each prompt/model combination was run three times per example (Figure 1).
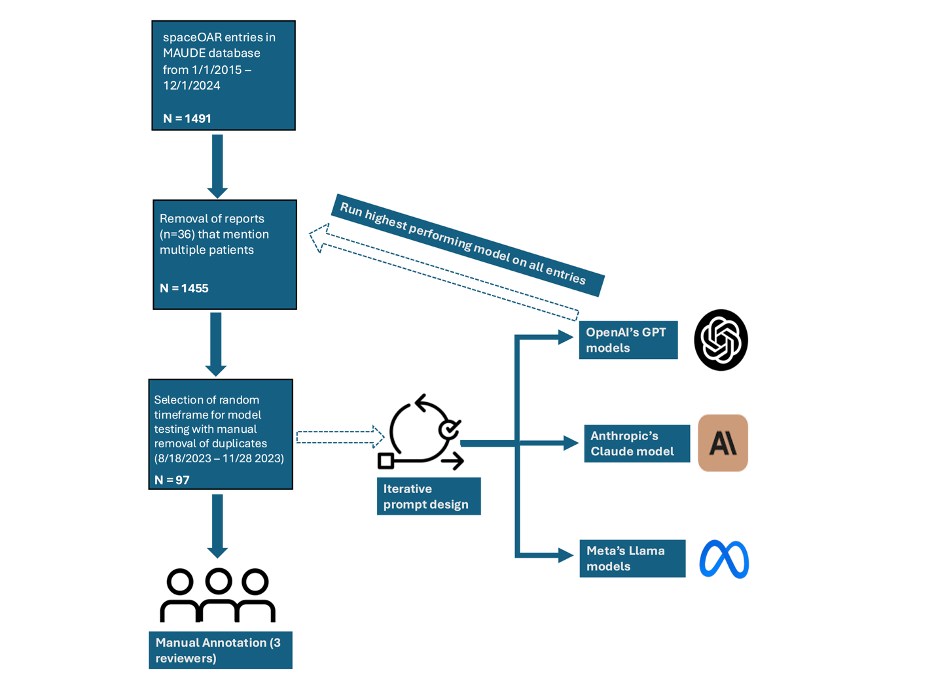
Figure 1: Flow diagram of documenting note selection and model testing.
The model with the strongest performance was selected to run on all the MAUDE data to date (June 1, 2015 – December 1, 2024) to create a full side effect profile (n = 1,455 reports).
Our results revealed that GPT-4o, using the joint prompt method and temperature of 0, yielded the most accurate results when compared with our reference document. When GPT-4o was on the entire dataset, the model revealed that the most common side effect was malpositioned gel (58.7%), followed by infection/inflammation/abscess (10.4%), fistula (7.1%), rectal ulcer (4.7%), pain (3.4%), and embolism of gel (3.4%). Urinary retention was noted to be the primary problem 1.5% of the time, anaphylactic reaction 1.2% of the time, DVT/PE 0.3% of the time, ICU level care 0.1% of the time, and death 0.3% of the time (Figure 2).

Figure 2: Primary and secondary problem count extracted from all SpaceOAR entries from June 2015 to December 2024.
For the assessment of whether the patient was symptomatic, 45.4% were symptomatic, 45.5% were not symptomatic, and 9.1% had an unknown status. Furthermore, 30.5% of patients had their symptoms initiated before radiation, 9.7% had symptoms after radiation started, 19.5% had an unknown status, and 40.3% were listed as “n/a” (listed as asymptomatic, therefore ineligible for this category). With regards to radiation planning, 20.1% of patients had a delay/change in their radiation plan, 24.7% had no delay/change, and 55.2% had an unknown status. Lastly, 45.0% had a CTCAE score of 1, 13.7% had a CTCAE score of 2, 32.3% had a CTCAE score of 3, 8.3% had a CTCAE score of 4, and 0.6% had a CTCAE score of 5.
Our analysis revealed that LLMs can accurately classify AEs from a diverse range of unstructured text inputs, as measured across several performance metrics, with OpenAI’s flagship GPT-4o model exhibiting the strongest overall performance for extracting data across all categories. Our findings provide a compelling case for the translational utility of LLMs for medical researchers to rapidly characterize and flag high-risk reports from the MAUDE database.
These tools can serve as a method of rapidly identifying higher risk reports (such as those initially classified as CTCAE 3+ or with high-risk features such as ICU level care, anaphylaxis, etc.), which can then be marked for further review. Our methodology also points to the utility of prompt engineering and LLM fine-tuning for improving the accuracy of these models for specific scenarios, such as medical device adverse event classification. Over time, increased validation of model results may ultimately lead to their independent use for medical research.
Written by: Nishan Sohoni,1 Nimit S. Sohoni,1 Ryan A. Sutherland,1 Vinaik M. Sundaresan,1 Shayan Smani,1 Prasanna Ananth,2 John A. Onofrey,3 Sanjay Aneja,4 Marcin Miszczyk,5 Ho-Joon Lee,6 Julia E. Olivieri,7 Michael S. Leapman1
- Department of Urology, Yale University, New Haven, CT, USA.
- Department of Pediatrics, Yale University, New Haven, CT, USA; Yale Cancer Outcomes, Public Policy and Effectiveness Research Center, New Haven, CT, USA.
- Department of Urology, Yale University, New Haven, CT, USA; Department of Radiology & Biomedical Imaging, Yale University, New Haven, CT, USA; Department of Biomedical Engineering, Yale University, New Haven, CT, USA.
- Department of Biomedical Engineering, Yale University, New Haven, CT, USA; Department of Therapeutic Radiology, Yale University, New Haven, CT, USA; Center for Outcomes Research and Evaluation, Yale University, New Haven, CT, USA.
- Department of Urology, Comprehensive Cancer Center, Medical University of Vienna, Vienna, Austria; Collegium Medicum Faculty of Medicine, WSB University, Dąbrowa Górnicza, Poland.
- Department of Genetics and Yale Center for Genome Analysis, Yale University, New Haven, CT, USA.
- Department of Computer Science, University of the Pacific, Stockton, CA, USA.