(UroToday.com) The 2023 American Urological Association Annual Meeting included a surgical technology and simulation session featuring work from Timothy Chu and colleagues presenting results of their study investigating the role of human rater bias in establishing ground truth in artificial intelligence (AI) development. AI is becoming an increasingly prominent tool that is used for a variety of urological purposes. The effectiveness of AI is dependent on ground truth, which is essentially the reality or “standard” that is being modeled by the supervised machine learning algorithm. However, because this ground truth is established by humans, ground truth and bias are intrinsically linked. In many scenarios, the ground truth is simply what the project owners deem “good enough” to create a good functioning model. This can be seen as an issue, especially in the context of medicine: errors can create serious consequences in regard to the health of patients. As such, this project sought to demonstrate the effects of using a methodical and thorough approach to developing ground truth to evaluate surgical performance.
Using the Mimic™ Flex VR robotic simulator, three different datasets were derived from VR suturing exercises. Three blinded, independent human raters were shown deidentified participant videos and were then asked to provide binary technical scores for various suturing skills, including needle positioning, entry angle, needle driving, and needle withdrawal. After a standardized four-round consensus building process (Fig 1a), these raters achieved score consensus after discussion. A particular area of interest was in tracking how often the minority score would become the ground truth to determine trends.

Across all exercises, a total of 5634 suturing skill assessments were included. After initial video review (Round 1), 32% of assessments had a review who provided a minority score. After an individual review of minority scores, or round 2, 44.1% of the minority scores persisted for group review. Of those minority scores that further persisted to round 3, 34.3% became the final ground truth score. It is interesting to note that out of all the original minority scores, 274/1816 (15.1%) persisted through the entire consensus building process and became the ground truth labels (Fig. 1b).
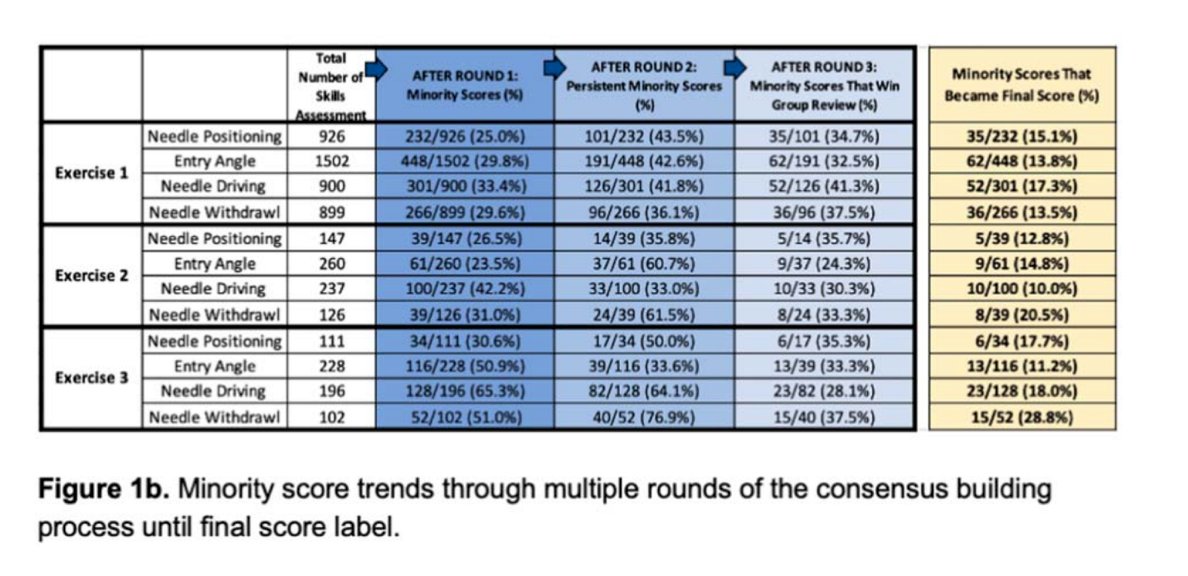
To conclude the presentation, Mr. Timothy Chu made it a strong point to emphasize that a considerable proportion of initial minority scores became the ground truth score, which held true across multiple datasets, raters, and scoring domains. This finding only serves to underline how a standardized consensus-building process is a crucial if not indispensable step in the creation of accurate machine learning models. It also underscores the significance of human bias on not only evaluations of surgical performance, but of potentially any machine learning algorithm. The improvement of these systems will only serve to benefit patients and create more effective incorporation into medical practice.
The audience and moderators alike demonstrated significant interest in the study, which they expressed through several comments and questions. The first comment arose from one of the moderators, who brought up the issue of peer pressure in the consensus-building process. He noted that the ability of the minority scorer to rally and convince their peers may play an undeniable role, as some scorers may also simply give up on their stance. Mr. Timothy Chu agreed that this does lead to another factor that only lends further support to the impact of human bias, as pride and even unique personalities can create variation. Furthermore, a question was raised by a different moderator regarding the existence of cases that had more than one answer, and if so, what the approach was for handling these situations. One of Mr. Chu’s colleagues from the audience decided to field this question as they stated that only 4 or 5 of the many cases looked over required the assistance of an established expert. However, even then, the answer was ambiguous, which was an instance that they went to great lengths to avoid when selecting cases for the study to begin with. One last comment from the moderator acknowledged the tedious nature of the project, with Mr. Chu closing the presentation to state that the 15% of initial minority scores that became final ground truth justifies the importance of doing this important work in improving machine learning algorithms to create optimization.
Presented by: Timothy Chu, Medical Student, USC Institute of Urology, Keck School of Medicine, University of Southern California, Los Angeles, California, USA
Written by: Kelvin Vo, Department of Urology, University of California Irvine, @kelvinvouci on Twitter during the 2023 American Urological Association (AUA) Annual Meeting, Chicago, IL, April 27 – May 1, 2023
References:
- Timothy Chu, Daniel I. Sanford, Elyssa Y. Wong, Runzhuo Ma, Cherine H. Yang, Istabraq S. Dalieh, Mitchell G. Goldenberg, Andrew J. Hung. Automated Surgical Skills Assessment: Consensus Building Towards Human-derived Ground Truth Scores for Machine Learning Algorithms [abstract]. In: American Urological Association Annual Meeting, April 28-May 1, 2023, Chicago, Illinois