Every test in medicine has two important attributes: precision and accuracy. The precision of a measurement system is the degree to which repeated measurement under unchanged conditions, show the same results. The accuracy of a measurement system is the degree of closeness of measurements of a quantity to that quantity’s true value. This led Dr. Tomaszewsky to discuss the topic of precision in identifying image features in prostate tissue sections, using artificial intelligence, or machine learning. The precision challenge is to identify significant prostate cancer from gland morphology, and also to differentiate the Gleason grade groups from one another, and most importantly differentiate non-clinically significant cancer (Gleason score of 6) from clinically significant cancer (Gleason score of 7 or above).
The traditional machine learning pipeline entails a structural hypothesis, creation of a “prior” (initial beliefs about an event in terms of the probability distribution), development of computational metrics representing “prior”, machine vision extraction of metrics and then a final decision of whether the disease exists or not. This is called a support vector machine classifier, which are supervised learning models. Human experts can provide actionable insights, and may bring these actionable insights in the form of a “prior”, which can function as an advanced starting point for an artificial intelligence system. The intuitive understanding of the world that humans possess – their reasoning and inferencing abilities, efficiency in learning, and the ability to transfer knowledge gained from one context to other domains are not understood easily by machines.
Dr. Tomaszewsky moved and tried to explain the problems of machine learning in prostate cancer. When analyzing prostate cancer, the micro acinus, the most basic unit of the prostate gland, is pathologically known to be the source of the disease. When trying to “teach” the computer to diagnose prostate cancer, we need to begin with gland segmentation, moving forward to gland classification with Markov random field iteration (set of random variables having a Markov property described by an undirected graph), as shown in figure 1.
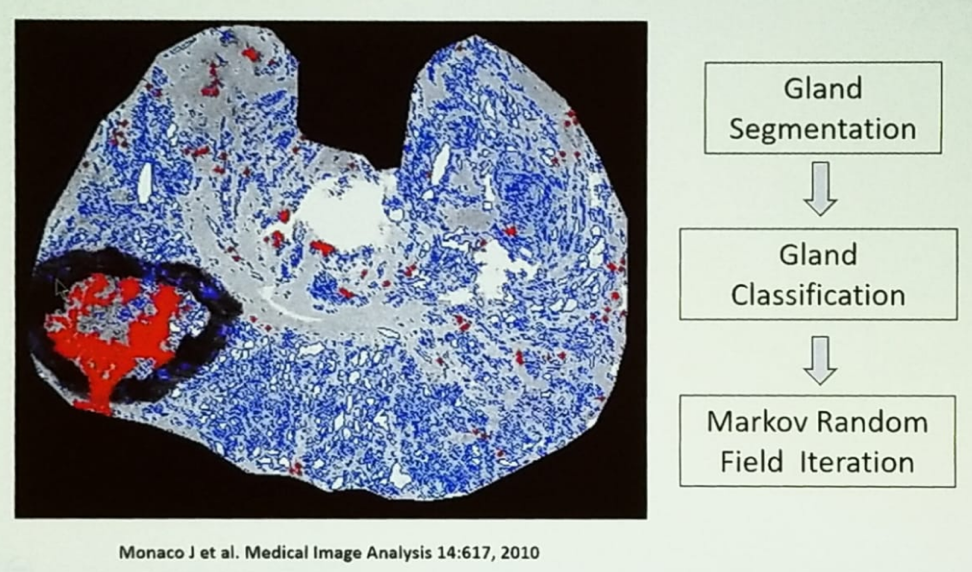
Figure 1: Overview of prostate cancer detection algorithm:
Using artificial intelligence, the computer can use different image modalities such as entropy, average, Gabo filter, and difference entropy, to differentiate between the different Gleason grades, as can be seen in figure 2.

Figure 2 – Different image modalities used to differentiate Gleason Grade:
The computer can also use morphometric feature extraction to diagnose and differentiate between different grades of the tumor. Other methods that weren’t detailed due to time constraints included the application of fractals (demonstrating differences between the same shapes of tissue by showing different intensity and texture).
A known problem is that of multidimensionality because in large multidimensional space it is always possible to find multiple solutions to a binary problem (disease exists or not). To avoid this multitude of solutions, one must reduce the dimensions of the data used for classification. This can be done through several techniques, including local linear embedding, isometric mapping, and spectral clustering. There are current investigations of other learning schemes for analyzing various very high-dimensional biomedical data.
Additional interesting findings Dr. Tomaszewsky mentioned in his complex discussion, was that the field effect around prostate cancer tissue provides clues on the progression of cancer. The tumor and its adjacent benign signature outperform prediction from cancerous regions alone.1 Additionally, multi-data fusion improves outcome prediction. This includes histologic data, mass spectroscopy data, and low dimensional embeddings. The combined embeddings result in a very good prediction model. All these things can be used in machine learning.
In summary, artificial intelligence consists of many factors, including traditional artificial intelligence, deep learning (which involved abstracting knowledge of a target domain simply by observing a large number of examples from the domain), one-shot learning, explainable artificial intelligence, cognitive artificial intelligence, and human input. The computer needs to see a large number of pathology datasets to be familiar with all varieties and options. Unfortunately, the existent pathology data sets are quite small. The challenges in building large histopathology data include the fact that data generation is limited in scope, hampered by proprietary software and lack of accepted standards. Additionally, large storage options are not generally available, and histopathology data requires large amounts of storage. Lastly, annotations are difficult, time-consuming, and application dependent.
Presented by: John Tomaszewski, MD, Peter A Nickerson Chairman of Pathology and Anatomical Sciences, University at Buffalo, Jacobs School of Medicine and Biomedical Sciences, Pathology and Anatomical Sciences Dept., University at Buffalo
References:
1. Lee et al. Eur Urol Focus 2016
Written by: Hanan Goldberg, MD, Urologic Oncology Fellow (SUO), University of Toronto, Princess Margaret Cancer Centre, @GoldbergHanan at the 70th Northeastern Section of the American Urological Association (NSAUA) - October 11-13, 2018 - Fairmont Royal York Toronto, ON Canada